@Entity = 테이블과 매핑하기 위해 필수 어노테이션
@Table = 엔티티와 매핑할 테이블을 지정
@Table(name=”student”)
기본 값은 엔티티의 이름을 소문자로 바꿔 사용한다.
ex) public class Student → student
hibernate.hbm2ddl.auto
옵션 설명
| create | 기존 테이블 삭제 후 다시 생성 |
| create-drop | create와 같으나 종료시점에 테이블 DROP |
| update | 변경분만 반영(운영DB에는 사용하면 안됨) |
| validate | 엔티티와 테이블이 정상 매핑되었는지만 확인 |
| none | 사용하지 않음 |
운영 장비에는 절대 create, create-drop, update 사용하면 안된다.
개발 초기 단계는 create 또는 update • 테스트 서버는 update 또는 validate • 스테이징과 운영 서버는 validate 또는 none
@Column(nullable = false, length = 10) - > 회원 이름 필수, 10자 이하
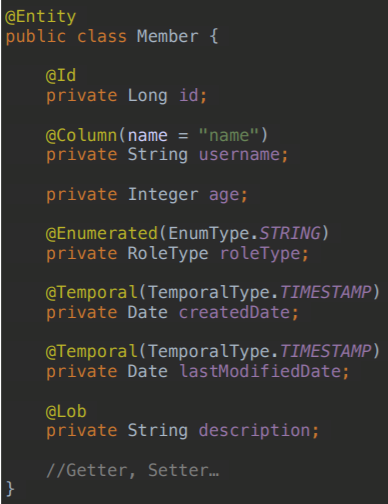
@Column 컬럼 매핑
@Temporal 날짜 타입 매핑
: LocalDate, LocalDateTime로 대체가능
@Enumerated(EnumType.STRING)으로 매핑해야 된다.
@Lob- 긴 길이의 스트링
기본 키 매핑 방법
직접 할당: @Id만 사용
자동 생성(@GeneratedValue)
- IDENTITY: 데이터베이스에 위임, MYSQL,PostgreSQL, SQL Server, DB2
- SEQUENCE: 데이터베이스 시퀀스 오브젝트 사용, ORACLE @SequenceGenerator 필수
- TABLE: 키 생성용 테이블 사용, 모든 DB에서 사용 @TableGenerator 필요
- AUTO: 방언에 따라 자동 지정, 기본값
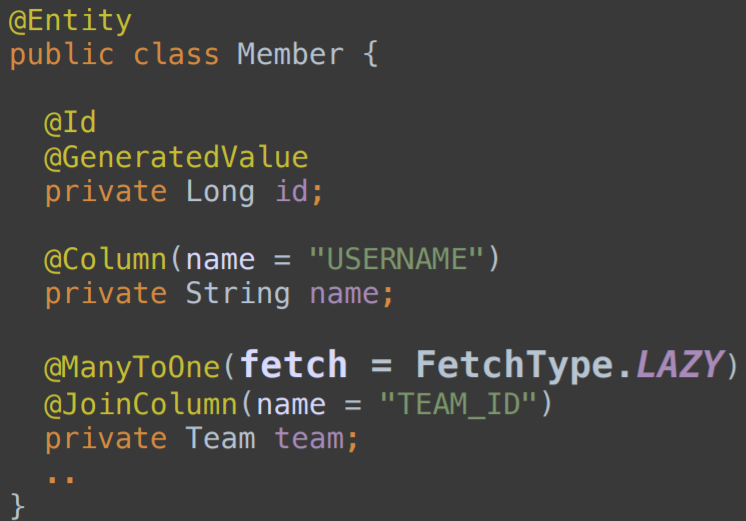
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
양방향 매핑시
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
양방향 매핑시 하는 실수
Member와 Team 관계 시
Team에만 멤버값을 넣어주고 Member에는 넣지않을때
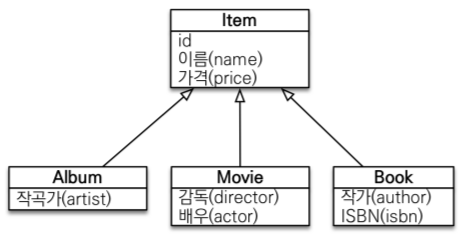
상속 관계 매핑

3가지 방법이 있다.

- @Inheritance()SINGLE_TABLE: 단일 테이블 전략
- TABLE_PER_CLASS: 구현 클래스마다 테이블 전략
- JOINED: 조인 전략
- @DiscriminatorColumn(name=“DTYPE”)
- @DiscriminatorValue(“XXX”)
조인 전략
장점
- 테이블 정규화
- 외래 키 참조 무결성 제약조건 활용가능
- 저장공간 효율성
단점
- 조회시 조인을 많이 사용한다.
- 쿼리가 복잡하다
- 저장 시 INSERT 쿼리가 2번 호출된다.
단일 테이블 전략


장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠름
- 조회 쿼리가 단순함
단점
- 자식 엔티티가 매핑한 컬럼은 모두 null 허용
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라서 조회 성능이 오히려 느려질 수 있다.
@MappedSuperclass
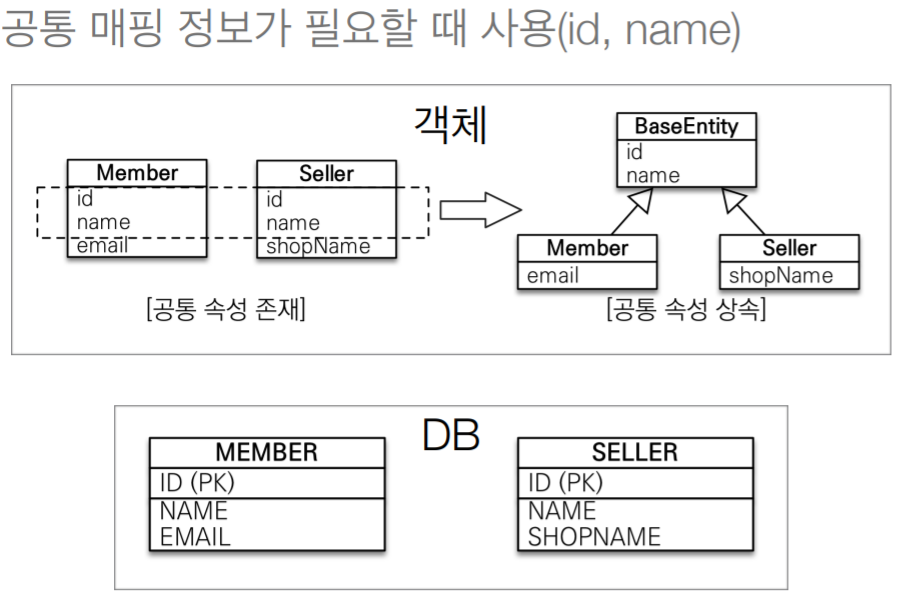
@MappedSuperclass은 주로 등록일,수정일 등 전체 엔티티에 공통 적용하는 정보일때 사용
@Getter
@Setter
@MappedSuperclass
public abstract class BaseEntity {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}
Member 클래스가 상속
@Entity
public class Member extends BaseEntity {
...
}
프록시와 연관 관계
프록시의 특징
실제 클래스를 상속 받아서 만들어짐 실제 클래스와 겉 모양이 같다. 사용하는 입장에서는 진짜 객체인지 프록시 객체인지 구분하지 않고 사용하면 됨(이론상)
프록시 객체는 실제 객체의 참조(target)를 보관 • 프록시 객체를 호출하면 프록시 객체는 실제 객체의 메소드 호출

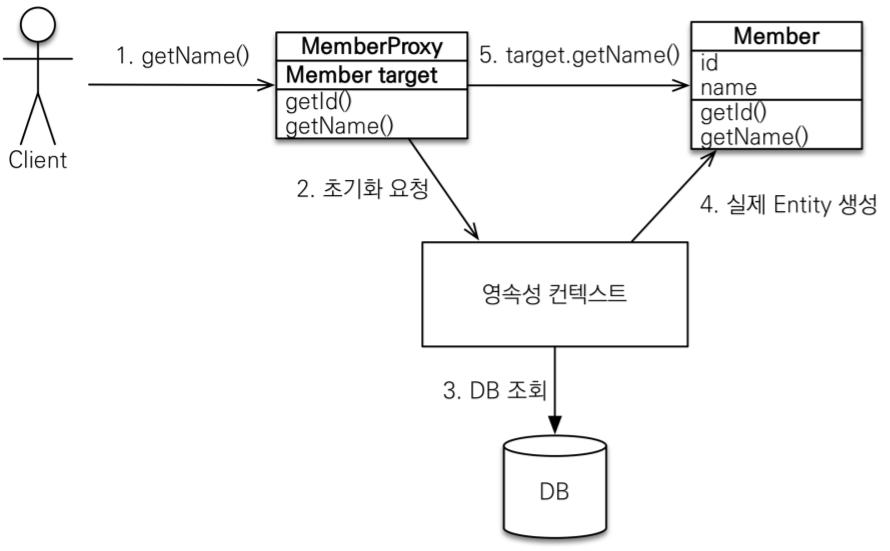
지연 로딩 LAZY을 사용해서 프록시로 조회
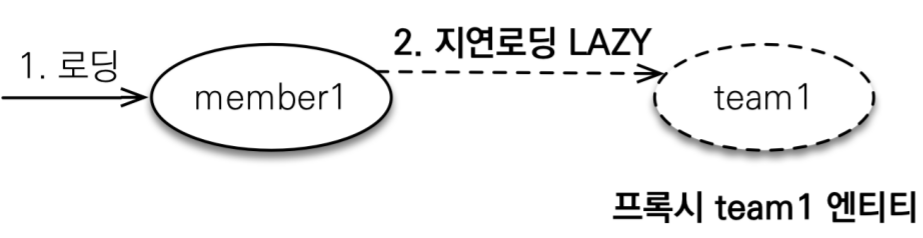
Member와 Team은 자주 함께 사용 -> 즉시 로딩 Member와 Order는 가끔 사용 -> 지연 로딩 Order와 Product는 자주 함께 사용 -> 즉시 로딩
모든 연관관계에 지연로딩을 사용하되 조회가 필요할때는 JPQL fetch 조인이나, 엔티티 그래프 기능을 사용하라
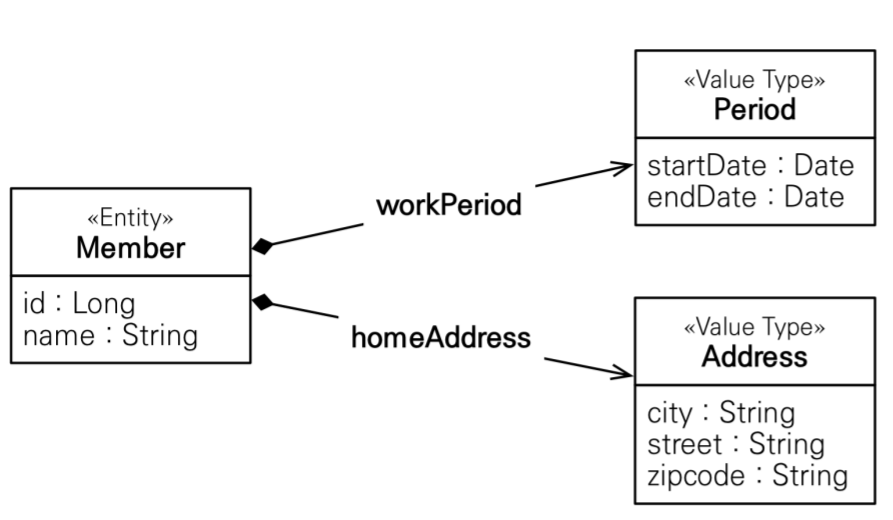
임베디드 타입
객체로 이뤄져 있어 복합 값을 가질수 있다.
@Embeddable: 값 타입을 정의하는 곳에 표시 • @Embedded: 값 타입을 사용하는 곳에 표시 • 기본 생성자 필수
회원이 상세한 데이터를 그대로 가지고 있는 것은 객체지향적이지 않으면 응집력만 떨어뜨립니다.
객체
@Entity
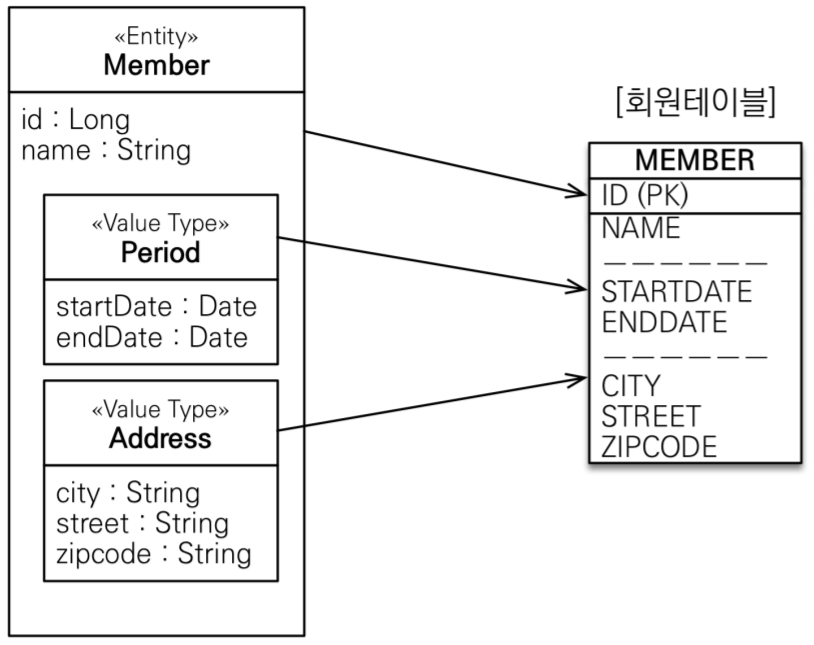
public class Member {
@Id @GeneratedVAlue
private Long id;
private String name;
@Embedded
private Period workPeriod; // 근무 기간
@Embedded
private Address homeAddress; // 집 주소
}
사용하는 쪽은 Embedded를 사용하고 선언된 객체는 Embeddable을 사용한다.
@Embeddable
public class Peroid {
@Temporal(TemporalType.DATE)
Date startDate;
@Temporal(TemporalType/Date)
Date endDate;
// ...
public boolean isWork (Date date) {
// .. 값 타입을 위한 메서드를 정의할 수 있다
}
}
@Embeddable
public class Address {
@Column(name="city") // 매핑할 컬럼 정의 가능
private String city;
private String street;
private String zipcode;
// ...
}
임베디드 타입은 기본 생성자가 필수
발생되는 문제- 만약 주소가 하나 더 필요하다고 하면??
임베디드 타입에 정의한 매핑정보를 재정의하려면 엔티티에 @AttributeOverride를 사용하면 됩니다.
예를 들어 회원에게 주소가 하나 더 필요하면 어떻게 해야 할까요?
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@Embedded
Address homeAddress;
@Embedded
Address companyAddress;
}
매핑 컬럼명이 중복돼서 문제가 실제 테이블에 들어갈 변수들이 두 개나 중복된다.
위의 Address companyAddress 코드를 @AttributeOverrides 로 재정의 해서 사용해야 한다.
@Embedded
@AttributeOverrides({
@AttributeOverride(name="city", column=@Column(name="COMPANY_CITY")),
@AttributeOverride(name="street", column=@Column(name="COMPANY_STREET")),
@AttributeOverride(name="zipcode", column=@Column(name="COMPANY_ZIPCODE"))
})
Address companyAddress;
실제 생성된 테이블은
CREATE TABLE MEMBER (
COMPANY_CITY varchar(255),
COMPANY_STREET varchar(255),
COMPANY_ZIPCODE varchar(255),
city varchar(255),
street varchar(255),
zipcode varchar(255),
...
)
만약 임베디드 타입이 null이 되면 그 안의 매핑 컬럼은 null이 된다.
불변 객체
값 타입은 불변 객체(immutable object)로 설계해야함
불변 객체: 생성 시점 이후 절대 값을 변경할 수 없는 객체
생성자로만 값을 설정하고 수정자(Setter)를 만들지 않으면 됨
값 타입: 인스턴스가 달라도 그 안에 값이 같으면 같은 것으로 봐 야 함
동일성(identity) 비교: 인스턴스의 참조 값을 비교, == 사용 • 동등성(equivalence) 비교: 인스턴스의 값을 비교, equals() 사용 • 값 타입은 a.equals(b)를 사용해서 동등성 비교를 해야 함 • 값 타입의 equals() 메소드를 적절하게 재정의(주로 모든 필드 사용)
객체지향 쿼리언어
JPQL 과 QueryDSL
JPQL
검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색
예시:: 이름중에 hello가 포함된 Member를 검색
String jpql = "select m From Member m where m.name like ‘%hello%'";
List<Member> result = em.createQuery(jpql, Member.class)
.getResultList();
예시
String jpql = "select m from Member m where m.age > 18";
List<Member> result = em.createQuery(jpql, Member.class)
.getResultList();
실행된 sql
실행된 SQL
select
m.id as id,
m.age as age,
m.USERNAME as USERNAME,
m.TEAM_ID as TEAM_ID
from
Member m
where
m.age>18
TypeQuery: 반환 타입이 명확할 때 사용 Query: 반환 타입이 명확하지 않을 때 사용
TypedQuery<Member> query =
em.createQuery("SELECT m FROM Member m", Member.class)
Query query =
em.createQuery("SELECT m.username, m.age from Member m")
JPQL의 결과 조회 API
query.getResultList(); return이 하나 이상 일때
query.getSingleResult(): 결과가 정확히 하나, 단일 객체 반환
단 결과가 없으면 NoResultException, 둘 이상이면 NonUniqueResultException
TypeQuery<Member> query = em.createQuery("select m from Member m", Member.class);
List<Member> resultList = query.getResultList();
iterator(Member member1 : resultList) {
System.out.println("member 1 : " + member1);
}
List<MemberDTO> resultNew = em.createQuery("select new com.jpa.MemberDTO(m.username, m.age) from Member m", MemberDTO.class).getResultList();
MemberDTO memberDTO = resultNew.get(0);
System.out.println("memberDTO.username = " + memberDTO.getUsername());
System.out.println("memberDTO.age = " + memberDTO.getAge())
프로젝션 - 조회할 대상을 지정한다.
SELECT m FROM Member m -> 엔티티 프로젝션 SELECT m.team FROM Member m -> 엔티티 프로젝션 SELECT m.address FROM Member m -> 임베디드 타입 프로젝션 SELECT m.username, m.age FROM Member m -> 스칼라 타입 프로젝션
DISTINCT로 중복제거할 수 있따.
페이징 API
JPA는 페이징을 다음 두 API로 추상화 • setFirstResult(int startPosition) : 조회 시작 위치 (0부터 시작) • setMaxResults(int maxResult) : 조회할 데이터 수
//페이징 쿼리 이름으로 조회하되 내림차순으로
String jpql = "select m from Member m order by m.name desc";
List<Member> resultList = em.createQuery(jpql, Member.class)
.setFirstResult(10) //시작 위치
.setMaxResults(20) // 조회 데이터 수
.getResultList();
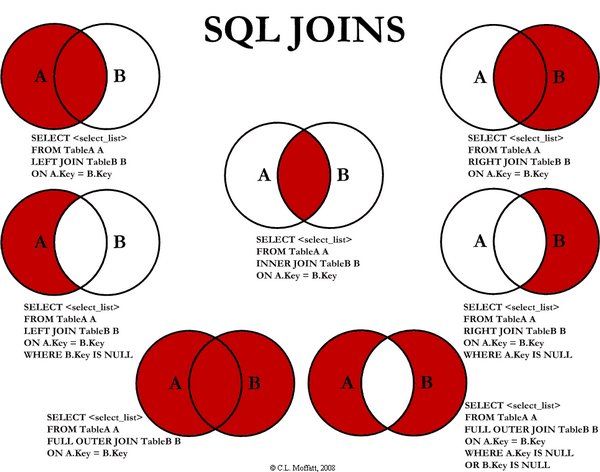
- 연관관계 있을때의 조인
예) 회원과 팀을 조인하면서, 팀 이름이 A인 팀만 조인
JPQL:
SELECT m, t FROM Member m LEFT JOIN m.team t on t.name = 'A'
SQL:
SELECT m.*, t.* FROM
Member m LEFT JOIN Team t ON m.TEAM_ID=t.id and t.name='A'
- 연관관계 없는 엔티티와의 조인
예) 회원의 이름과 팀의 이름이 같은 대상 외부 조인
JPQL:
SELECT m, t FROM
Member m LEFT JOIN Team t on m.username = t.name
SQL:
SELECT m.*, t.* FROM
Member m LEFT JOIN Team t ON m.username = t.name
JPQL의 서브 쿼리
나이가 평균보다 많은 회원 select m from Member m where m.age > (select avg(m2.age) from Member m2)
한 건이라도 주문한 고객 select m from Member m where (select count(o) from Order o where m = o.member) > 0
JPQL - 페치 조인(fetch join)
SQL 조인이 아니라 JPQL에서 최적화를 위해 제공하는 기능
엔티티 페치 조인
[JPQL]
select m
from Member m
join fetch m.team
[SQL]
SELECT M.*, T.*
FROM MEMBER M
INNER JOIN TEAM T
ON M.TEAM_ID=T.ID
String jpql = "select m from Member m join fetch m.team";
List<Member> members = em.createQuery(jpql, Member.class)
.getResultList();
for (Member member : members) {
//페치 조인으로 회원과 팀을 함께 조회해서 지연 로딩X
System.out.println("username = " + member.getUsername() + ", " +
"teamName = " + member.getTeam().name());
}
컬렌션 페치 조인
일대다 관계, 컬렉션 페치 조인으로 책과 카테고리가 있을때 IT 카테고리를 보고 싶을때
[JPQL]
select distinct t //distinct를 추가하면 sql,애플리케이션에서 중복을 제거한다.
from Team t join fetch t.members
where t.name = ‘팀A'
[SQL]
SELECT T.*, M.*
FROM TEAM T
INNER JOIN MEMBER M ON T.ID=M.TEAM_ID
WHERE T.NAME = '팀A'
String jpql = "select t from Team t join fetch t.members where t.name = '팀A'"
List<Team> teams = em.createQuery(jpql, Team.class).getResultList();
for(Team team : teams) {
System.out.println("teamname = " + team.getName() + ", team = " + team);
for (Member member : team.getMembers()) {
//페치 조인으로 팀과 회원을 함께 조회해서 지연 로딩 발생 안함
System.out.println(“-> username = " + member.getUsername()+ ", member = " + member);
}
}

그러나 두 번씩 조회된다.
페치 조인과 DISTINCT
- SQL에 DISTINCT를 추가
- 애플리케이션에서 엔티티 중복 제거
페치 조인과 일반 조인의 차이
select t
from Team t join t.members m
where t.name = ‘팀A'
- 페치 조인을 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩)
- 페치 조인은 객체 그래프를 SQL 한번에 조회하는 개념
페치 조인을 하게 되면 페이징 API setFirstResult,setMaxResults를 사용할 수 없다.
장점은 연관된 엔티티들을 SQL문 한번으로 전부 조회된다. FetchType을 사용하는 것보다 우선적으로 사용한다. 무조건 FetchType을 Lazy로 설정하고 최적화가 필요할 때 페치 조인을 적용하게 된다.

벌크 연산
재고가 10개 미만인 모든 상품의 가격을 10% 상승하려면???
JPA 변경 감지 기능으로 실행하려면 너무 많은 SQL 실행된다.
벌크 연산 한번으로 테이블 값을 변경한다.
String qlString = "update Product p " +
"set p.price = p.price * 1.1 " +
"where p.stockAmount < :stockAmount";
int resultCount = em.createQuery(qlString)
.setParameter("stockAmount", 10) //이름과 실제 값이 파라미터로 들어간다.
.executeUpdate(); //변경된 엔티티 수를 반환하게 된다.
벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리 벌크 연산을 먼저 실행
벌크 연산 수행 후 영속성 컨텍스트 초기화
QueryDSL
컴파일 시점에 문법 오류를 찾을 수 있음 동적쿼리 작성 편리함 단순하고 쉬움 실무 사용 권
JPAFactoryQuery query = new JPAQueryFactory(em);
QMember m = QMember.member;
List<Member> list =
query.selectFrom(m)
.where(m.age.gt(18))
.orderBy(m.name.desc())
.fetch();
김영한 핵심 원리를 수강하고 참고하였습니다.
'스프링 부트 > JPA' 카테고리의 다른 글
| [스프링] DATA JPA In절로 파라미터 넣기 (0) | 2022.08.25 |
|---|---|
| [스프링] @Query에 ENUM 타입 쓰는 법 (0) | 2022.08.25 |
| @NotNull, @NotEmpty, @NotBlank 차이 (0) | 2022.02.19 |
| 스프링 부분 수정 쿼리 @DynamicUpdate (1) | 2022.02.18 |
| 스프링부트 JPA N+1 문제와 해결 방법 (0) | 2022.01.18 |

댓글